Eliciting Confidence for Improving Crowdsourced Audio Annotations
Mendez, A.E.M., Cartwright, M., Bello, J.P., Nov, O. Eliciting Confidence for Improving Crowdsourced Audio Annotations. In Proceedings of the ACM on Human-Computer Interaction, vol. 6(CSCW1), 2022.
Abstract
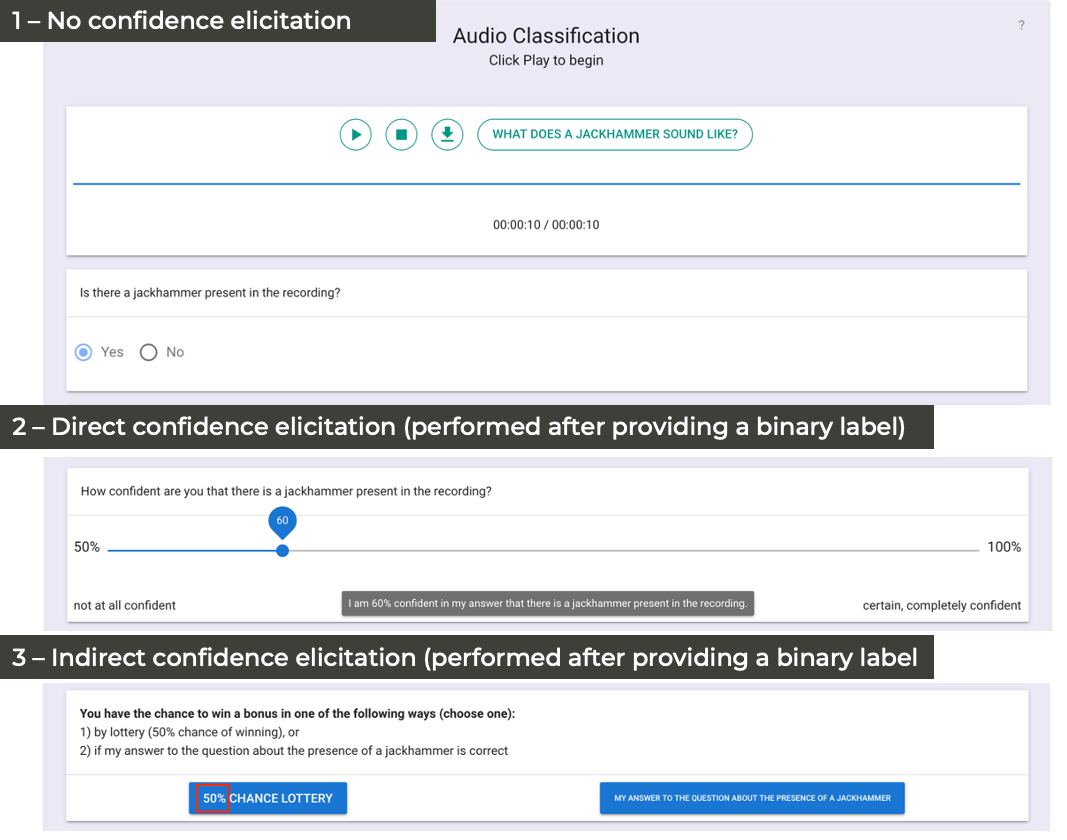
In this work we explore confidence elicitation methods for crowdsourcing "soft" labels, e.g., probability estimates, to reduce the annotation costs for domains with ambiguous data. Machine learning research has shown that such "soft" labels are more informative and can reduce the data requirements when training supervised machine learning models. By reducing the number of required labels, we can reduce the costs of slow annotation processes such as audio annotation. In our experiments we evaluated three confidence elicitation methods: 1) "No Confidence" elicitation, 2) "Simple Confidence" elicitation, and 3) "Betting" mechanism for confidence elicitation, at both individual (i.e., per participant) and aggregate (i.e., crowd) levels. In addition, we evaluated the interaction between confidence elicitation methods, annotation types (binary, probability, and z-score derived probability), and "soft" versus "hard" (i.e., binarized) aggregate labels. Our results show that both confidence elicitation mechanisms result in higher annotation quality than the "No Confidence" mechanism for binary annotations at both participant and recording levels. In addition, when aggregating labels at the recording level, results indicate that we can achieve comparable results to those with 10-participant aggregate annotations using fewer annotators if we aggregate "soft" labels instead of "hard" labels. These results suggest that for binary audio annotation using a confidence elicitation mechanism and aggregating continuous labels we can obtain higher annotation quality, more informative labels, with quality differences more pronounced with fewer participants. Finally, we propose a way of integrating these confidence elicitation methods into a two-stage, multi-label annotation pipeline.