Two Papers at WASPAA 2021
We have two new papers at WASPAA 2021 this year:
Weakly Supervised Source-Specific Sound Level Estimation in Noisy Soundscapes
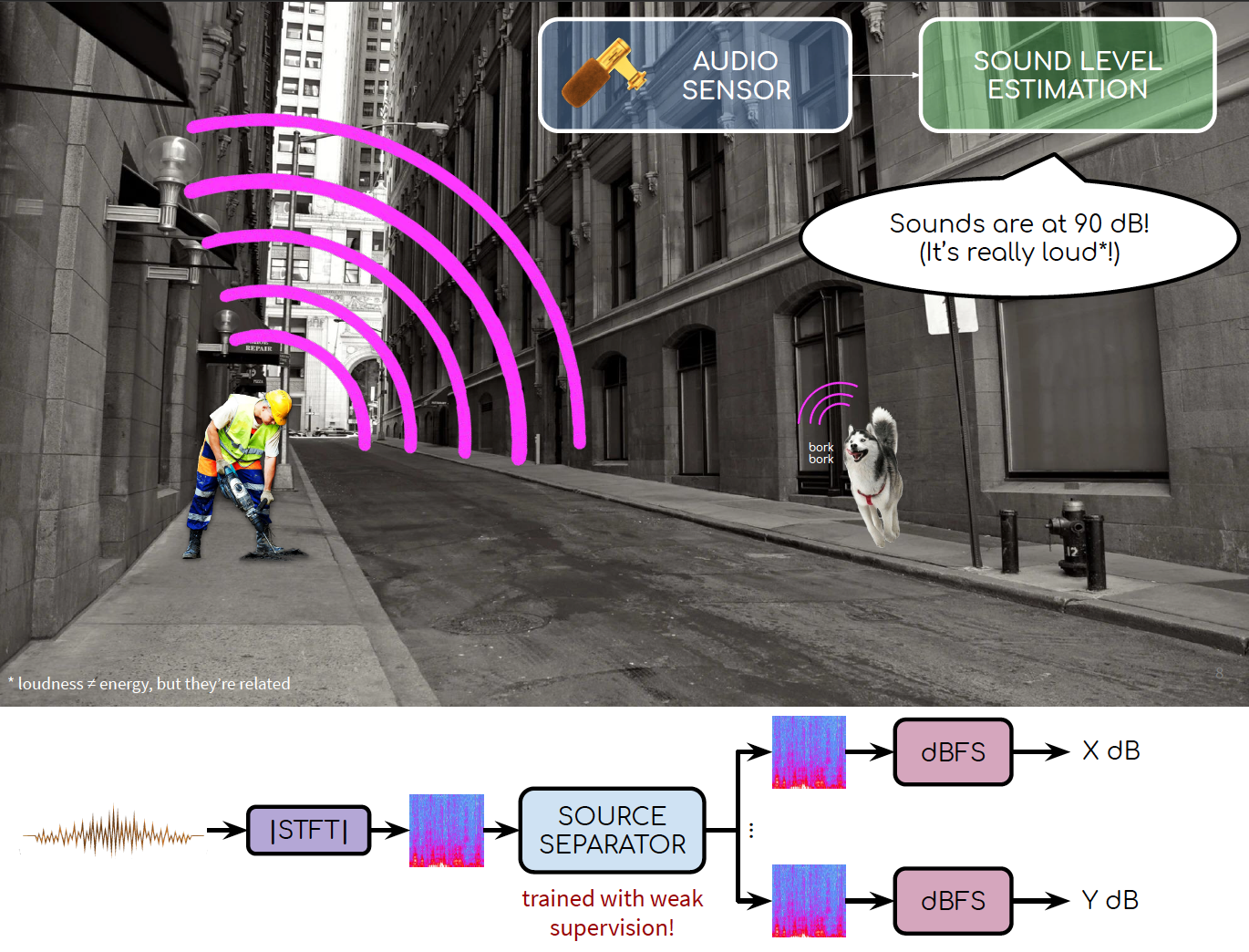 “Weakly Supervised Source-Specific Sound Level Estimation in Noisy Soundscapes” led by Aurora Cramer. While the estimation of what sound sources are, when they occur, and from where they originate has been well-studied, the estimation of how loud these sound sources are has been often overlooked. This paper propsoes a model to estimate how loud specific classes of sounds are within an audio mixture using only weak supervision and allowing for the presence of background noise, thus supporting training with real-world data.
“Weakly Supervised Source-Specific Sound Level Estimation in Noisy Soundscapes” led by Aurora Cramer. While the estimation of what sound sources are, when they occur, and from where they originate has been well-studied, the estimation of how loud these sound sources are has been often overlooked. This paper propsoes a model to estimate how loud specific classes of sounds are within an audio mixture using only weak supervision and allowing for the presence of background noise, thus supporting training with real-world data.
As part of this paper, we are releasing a new dataset SONYC-Backgrounds, a dataset of “urban backgrounds” from the SONYC sensor network. This a very useful dataset when synthesizing controlled datasets for machine listening experiments!
Who calls the shots? Rethinking few-shot learning for audio
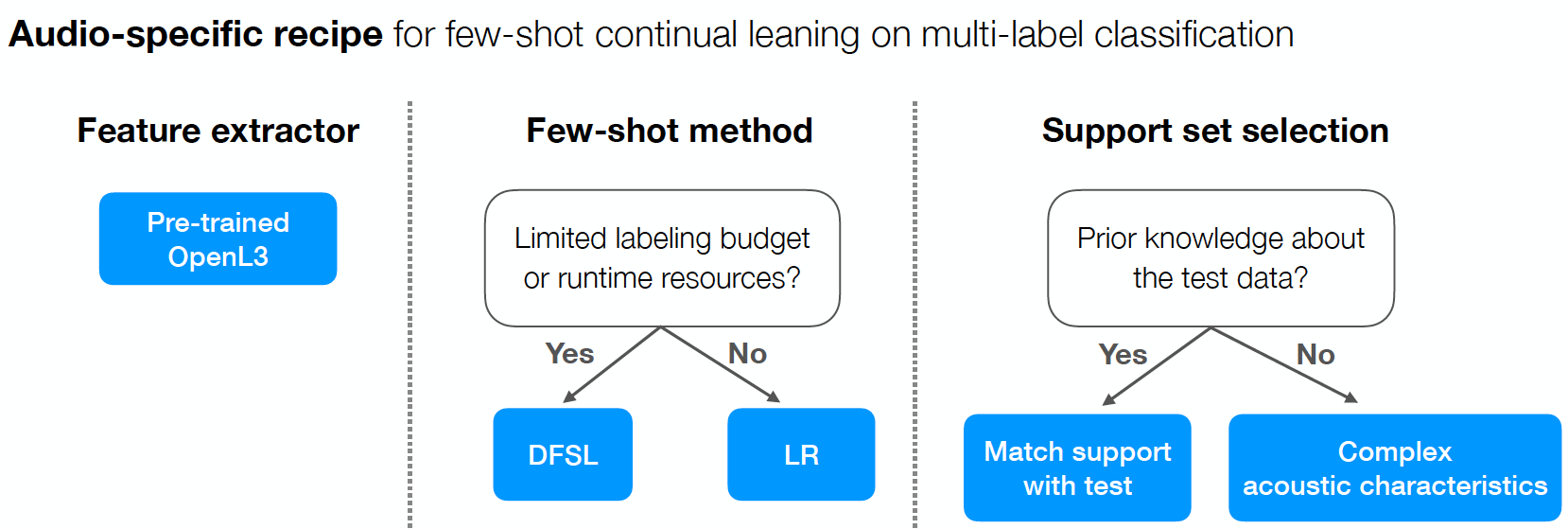 “Who calls the shots? Rethinking few-shot learning for audio” led by Yu Wang. Through a series of experiments, this paper investigates questions in audio few-shot learning concerning the impact audio properties such as SNR and polyphony may have on system design, performance, and human-computer interaction. In doing so, we provide recommendations for constructing support sets and for when to transition from a few-shot to standard training regime.
“Who calls the shots? Rethinking few-shot learning for audio” led by Yu Wang. Through a series of experiments, this paper investigates questions in audio few-shot learning concerning the impact audio properties such as SNR and polyphony may have on system design, performance, and human-computer interaction. In doing so, we provide recommendations for constructing support sets and for when to transition from a few-shot to standard training regime.
As part of this paper, we are releasing two new synthetic FSD50k-derived datasets, FSD-MIX-CLIPS and FSD-SED, both very useful for analyzing the impact of polyphony and SNR in audio recognition models.