TriCycle: Audio Representation Learning from Sensor Network Data Using Self-Supervision
Cartwright, M., Cramer, J., Salamon, J., Bello, J.P. TriCycle: Audio Representation Learning from Sensor Network Data Using Self-Supervision. In Proceedings of the IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), 2019.
Abstract
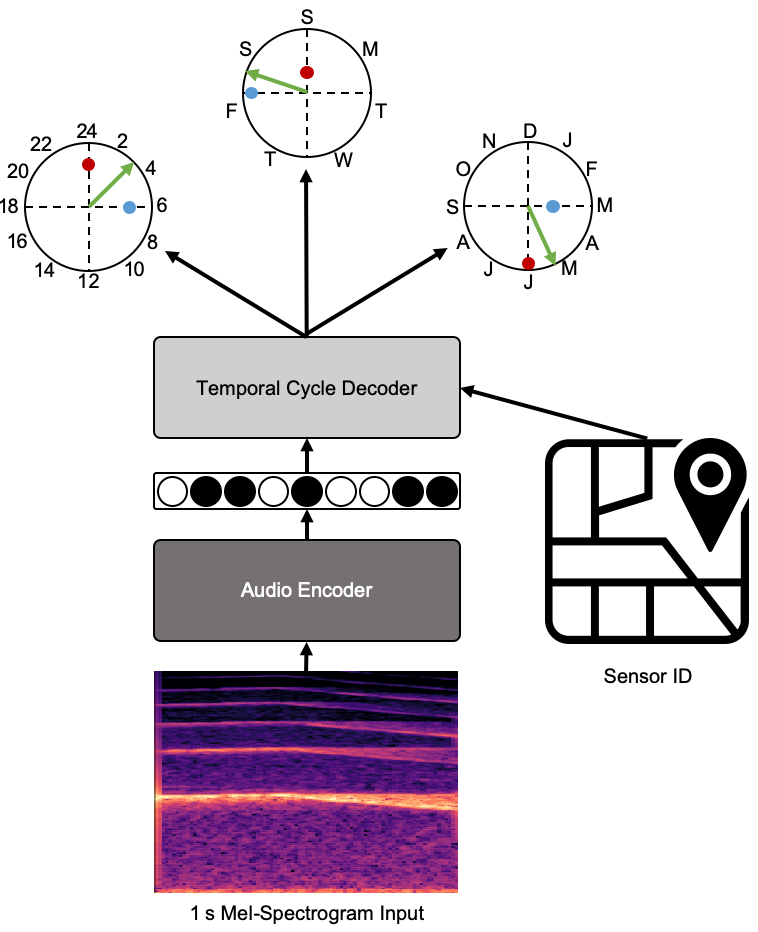
Self-supervised representation learning with deep neural networks is a powerful tool for machine learning tasks with limited labeled data but extensive unlabeled data. To learn representations, selfsupervised models are typically trained on a pretext task to predict structure in the data (e.g. audio-visual correspondence, short-term temporal sequence, word sequence) that is indicative of higher-level concepts relevant to a target, downstream task. Sensor networks are promising yet unexplored sources of data for self-supervised learning—they collect large amounts of unlabeled yet timestamped data over extended periods of time and typically exhibit long-term temporal structure (e.g., over hours, months, years) not observable at the short time scales previously explored in self-supervised learning (e.g., seconds). This structure can be present even in singlemodal data and therefore could be exploited for self-supervision in many types of sensor networks. In this work, we present a model for learning audio representations by predicting the long-term, cyclic temporal structure in audio data collected from an urban acoustic sensor network. We then demonstrate the utility of the learned audio representation in an urban sound event detection task with limited labeled data.